火车头伪原创内容出现【\h\】、【\s\】符号怎么办?
由于采集的目标网站的站长制作水平各不相同,经常出现html书写不规范、标签未闭合等情况,造成各种如题的异常情况。一般可以通过火车头采集规则的调整来解决异常问题。
问题:例如有网友出现伪原创内容有【\h\】、【\s\】符号。

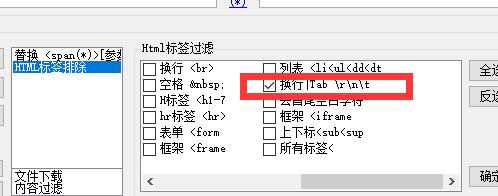
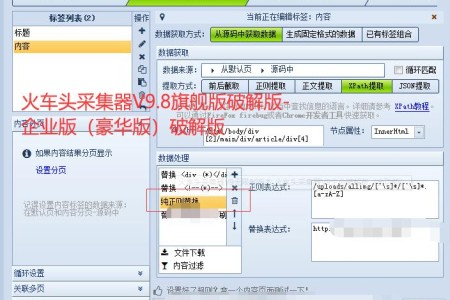
解决方法:如下图,任务进行HTML标签排除,勾选:strong加粗、换行tab \r\n\t 、去首尾空白字符这三个标签。
HTML标签处理的建议:
1、strong加粗(必选)、换行tab \r\n\t(必选)、去首尾空白字符(必选)
2、其它标签,在不影响内容的情况下尽量勾选,以提高伪原创效果。
采集案例分析,附上目标站源码

目标网页源码
文章采用了p、span、article以及div混排的方式,还包含了\r \n等特殊符号。
给该网友的解决方案:
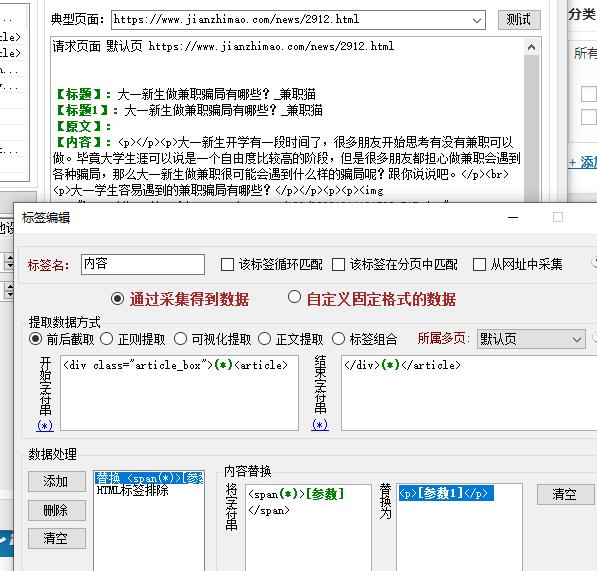
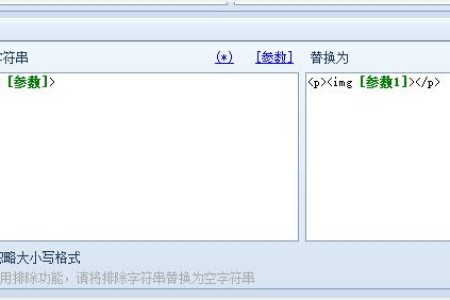
一、默认会清除span标签,因此可在火车采集器规则中,将span替换为p标签。
<span(*)>[参数]</span> 替换为 <p>[参数1]</p>
二、出现【\h\】是因为插件未对/r /n等特殊换行符处理,因此可在火车头规则中,html标签清除中勾选 清除换行符。
感谢大家对小男孩伪原创的关注,后期可以举一反三,将目标网页稍加处理简洁后再进行伪原创处理。
扩展阅读:


火车头伪原创内容出现【\h\】、【\s\】符号怎么办?:等您坐沙发呢!