为什么我的伪原创插件到期了,却还能正常使用? 由于近期工作繁忙,到期用户未及时关闭,小北也就默许用户可以继续使用。 在到期后关停前,小北会QQ联系并通...
长话短说,好记性不如一个烂笔头,把优化细节都记录下来 帝国cms优化攻略请前往:https://www.xiaoboy.cn/jiqiao/305.html 一、WP的js和css的文件优化 1、das...
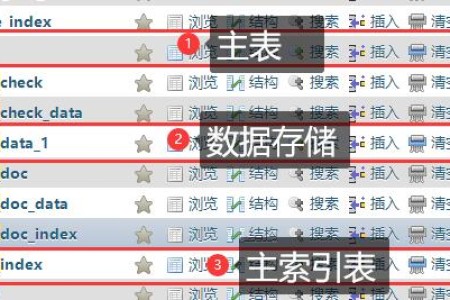
人到中年,记性不如当年。好记性不如一个烂笔头,于是打算把网站优化中的繁多细节都记下来,方便自己,也方便别人。 本篇为帝国CMS优化攻略,同时开了篇WP优...
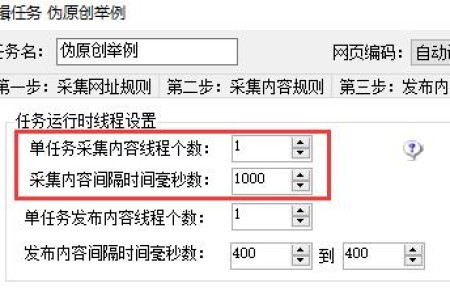
小男孩伪原创插件不限制采集条数,但需要设置单任务线程为1,采集间隔为1000毫秒以上。 如下图所示: 一、如果采集频率过高,会造成任务拥堵导致延时过高,...
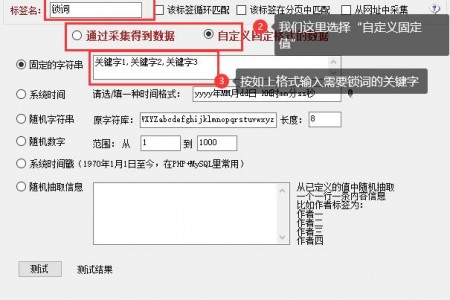
小男孩伪原创有锁词功能了! 什么是锁词? 就是针对一些词汇,不需要进行伪原创处理,所以屏蔽处理。 火车头插件如何锁词? 1、打开火车头,新建标签,名称为...

由于采集的目标网站的站长制作水平各不相同,经常出现html书写不规范、标签未闭合等情况,造成各种如题的异常情况。一般可以通过火车头采集规则的调整来解决...

火车采集器伪原创php插件 下载说明及使用说明: 1、请下载后解压到火车采集器的\Plugins\LocoySpider\ 文件夹。 2、火车采集器伪原创插件的图文教程(新手必...
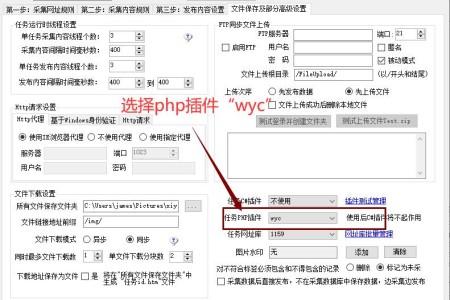
简单几步,即可开始火车头伪原创之旅。 下载小男孩伪原创php插件(支持火车头所有版本),下载地址:http://www.xiaoboy.cn/d/tool/53.html 第一步:将wyc.php...
宝塔面板的服务器,主要存在以下几处日志缓存,需要定期清理,否则在高访问量下很容易出现几G甚至几十G的磁盘占用。 一、网站监控报表的日志 路径:/www/serv...
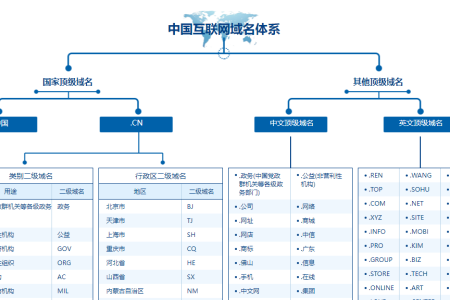
快速查找:CTRL+F 后缀 备注 .中国 - .cn - .政务.cn 中国党政群机关等各级政务部门 .公益.cn 非营利性机构 .gov.cn ...
163骨干:ChinaNet(也叫 163 骨干网,AS4134), ip以202.97开头. 定位于承载普通质量的互联网业务, 基建早, 带宽大, 便宜。因为用的人多,并且优化程度低,因...
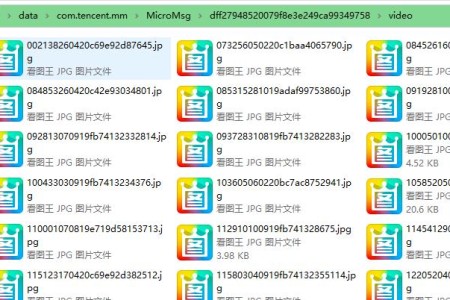
很多人换手机时担心数据丢失的问题,其中微信聊天记录里的图片和视频占用了极大的存储空间。 定期将它备份并清空手机,是一个很多的手机使用习惯。 在百度一...

是的,您可以删除 /www/server/data/mysql-slow.log 文件。这是 MySQL 的慢查询日志文件,用于记录执行时间较长的 SQL 查询语句。删除该文件通常不会对 MySQL...
二者各有利弊,memcached使用内存,因此速度更快,文件走硬盘,速度要慢很多,约前者的二倍时间。 But!Memcached很贵,因为你可以有40G硬盘,但你往往没有40...
宝塔面板可以通过API实现批量添加防火墙IP 适用于多台服务器,以及需要增加多个IP或者IP段的情况。 以上只是告诉你解决方案,如何实施并不做介绍。能&不...
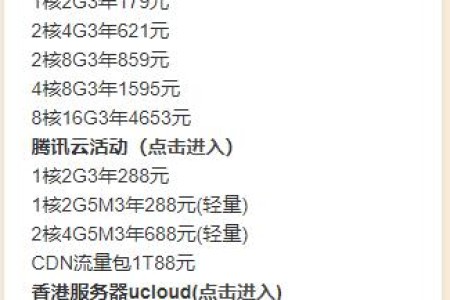
如下图,保留了两年多,是时候下架展板了。其实最低价服务器当属2022年2月份,腾讯云轻量2核4G6M 3年也不到300元。 其实现在大厂的服务器活动力度有限,阿里...
如下,分div和style两部分,可以一起放置于body内任意位置。 <style> .deng-box1 { position: fixed; top: -30px; le...
第一步:下载安装composer curl -sS https://getcomposer.org/installer | php 第二步:进入项目所在文件夹,执行 php composer.phar require fabp...
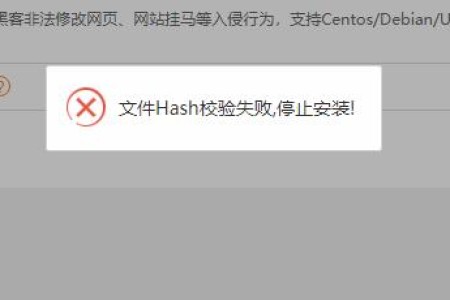
宝塔的文件搜索及批量修改软件[作者牧飞] 确实好用,完全免费,整个商城有且只有这一款软件。 最近遇到安装失败的问题,提示:“文件Hash校验失败,停止安装!” ...
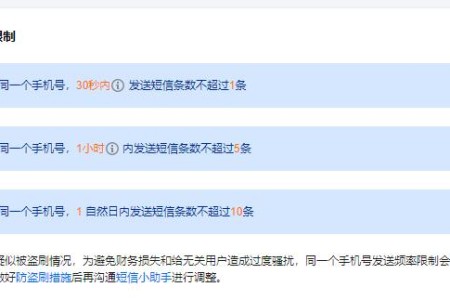
头部IDC的短信限制都比较严苛,正常使用起来没什么毛病,延时极低。单价基本都在5分钱每条,遇到活动可以打个折扣,达到1000条9.9元(1分钱一条)的价格。 估计...