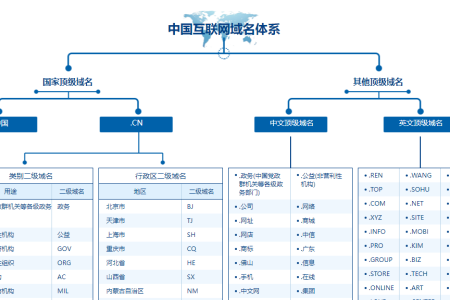
2021年逆向推理的SEO排名规则研究
小编前言:现在SEO圈潜心研究算法和排名的人越来越少,愿意写出来的人更是屈指可数。这类SEO排名算法的技术文章往往最终沦为快排圈用来收割的软文。
以下文章仅为网友ZERO的观点,小编觉得某些方面的切入点还是值得探究,便转发此文给大家,与君共勉。
追加:随着第二篇及后面文章的阅读,以及深入了解网友ZERO,得知这位博主是位SEO优化站长,靠SEO优化吃饭的,因此本篇及其它也算软文一篇了。因此对于某些夸大的部分自行鉴别,毕竟部分内容还是可以起到“温故而知新”的功效。
目前小编主要靠自己做站养站为生,因此暂不存在恰饭的SEO技术性软文。
小编对于SEO的认知依旧是内容为王外链为辅,即便被这两年各种快排和桔子、5118等工具刷新了认知后,我还是坚持这个认知观点。
时间:2021-3-5 23:34
搜索引擎的排名规则是完全黑箱化的,其中,只有很个别的规则在百度搜索资源平台,或是百度专利里面可以看到。而大部分规则,对于非百度内部人员是无从得知的。
甚至,因为搜索引擎在排名规则上大量采用了机器学习的方法,而机器学习,尤其深度学习通常本身就是黑箱化的,这导致了哪怕百度内部人员也并没有对排名规则有非常确切的把握。(在这篇文章里面有具体阐述这个观点:通过浏览价值增益,闭着眼睛将SEO流量翻几倍)
哪怕搜索引擎的规则本身是黑箱的,但有趣的是,最终排名现象又是完全公开化的——任何人都可以低成本的获取到全网的排名情况。因此,我们可以有大量的统计数据,去「倒推」搜索引擎的排名规则。
我们已经知道了排序「结果」,要反过去搞明白是什么排序规则作为其「原因」,从而塑造了这样的最终结果,这就是倒推。
倒推,又称反向推理、解析推理或是溯因推理。它似乎没有比较统一的名称,从这一点就可以看出,它在学界还不像是一个特别成型的推理方法。与之平行的归纳推理和演绎推理,要远远比它更加的广为人知。
尽管在过去的很多年里面溯因推理都是我研究SEO的主要方式,但直到不久前,我都没有在比较纯粹的逻辑学角度去专门研究它。因此,本文很可能会有一些说辞不严谨的地方,而且,这篇文章能涉及到的深度也会比较有限。
如果有人对数学(统计)/哲学(逻辑学)有较多了解,很期望能有所交流。
逻辑这种东西,时常是被不自觉运用到的。当我正式意识到溯因推理应当是SEO的主要研究方向,已经是很晚的时候了,是在大约一年多以前。
当时在看爱因斯坦所著的《物理学的进化》,其中频繁提到:物理学是通过观察到的现象,再去找到可以解释这些现象的原因,这和福尔摩斯探案本质上是相似的,福尔摩斯先了解到的是被凶杀等的结果,随之再是推测凶手的动机及作案手法等等。
随之我看了《福尔摩斯探案集》,这部小说集里面以福尔摩斯给华生科普讲解的形式时常提起:解析推理这种反过来思考的方式,是和常规正向思考方式有所不同的,是大部分人都未曾掌握的。
物理学在内的部分学科的学术研究,以及侦探探案,是以反向推理为核心的领域,这样的领域似乎不算很多,大部分行业看起来还是以正向推理为核心的。
病理诊断也是溯因推理为核心的领域。《豪斯医生》这部电视剧中,每当病人出现一个新的症状的时候,医生就会兴奋起来。看似病人的疾病是加重了,但越多的症状(结果)就越容易去反向推理出病因。知道了病人实际患的究竟是什么病,从而才能有效治疗。
搜索引擎的排名研究和病理诊断也是一样的,不同的原因(排序因素/病源)可能导致多个相同的结果(不同排名区间分布下的排名好坏差异/多个症状)。多因多果的分析从来就是一个烧脑子的问题。
从学术一点的角度,比较普及的因果关系研究方法,似乎当属近代的「穆勒五法」。穆勒五法的基本思路不难理解,说起来却又拗口,就不在这篇文章展开了。大体上来说,穆勒五法更多是以归纳法去提出假说,属于很基础的范畴。
(但其中「共变法」比较特殊,不完全属于归纳法范畴,而是去看了时间线上的动态变化。AB测试是共变法的思路)
比如在我的这篇文章里面,在统计了数据之后,主要需要使用的就是穆勒五法范围里面的手段去进行研究。例如很简单的研究面包屑导航是否管用的例子,正属于穆勒五法里面的「契差法」。
进一步的,在实际研究分析过程中,越是页面布局简单的排名特例,越是具有分析价值,应该用于重点分析。因为页面越简单,可能引起排名变化的地方越少,那么剩余的地方就更可能是真正影响排名的地方。这则是穆勒五法里面的「剩余法」。
如果不去研究这么学术化的东西的话,用人话来说,一般把这些叫做研究共性、差异性与研究特例。只要掌握这种分析思路,在SEO这种平均研究水平极其浅薄的领域,通常已经足够有很好的成绩。在SEO行业里面,附子、房总是我看到过的也曾提起过「共性」、「差异性」这些词的人,他们都是至少手头有几十万日流量的站的。
这一小段很可能会比较难以理解,主要是我自己就还没探索明白。只是先写在这里,看是否有人有一些想法可以共同研究。不很感兴趣的可以跳到下一节。
尽管穆勒五法作为一个对于溯因推理方法的系统性总结,肯定是有其价值的,但至少对我而言,在研究突破方面能帮到的似乎着实有限。在2014年左右的时候,我已经有大规模的运用这些方法进行分析了。
有一本近几年的,以机器学习为主要方向的研究因果推断的书《为什么》,其中提到了研究因果关系的三个逐步递进的阶梯:
- 基于被动去统计观察的(穆勒五法整体上处于这个阶段)
- 基于主动去干涉影响的(穆勒五法里面的共变法,或是其应用之一AB测试处于这一阶段)
- 基于主动去探索未发生状态的
第二级,是如果不存在这个原因,我们促使这个原因发生,看结果会变成什么样;
第三级,是如果已经存在这个原因,我们假设这个原因没发生,看结果会变成什么样。
在看这本书之前,我已经想到第三级是应该探索的范围,从而用深度学习进行了研究尝试。
举个例子,先提取了网页上的面包屑、相关文章、热门文章等区块,用这些区块的出现与否和实际排名,用深度学习去进行训练来拟合。进一步的,测试集里面有相关文章区块的网页,其中的相关文章区块去除掉,然后再用前面跑好的模型来预测,看排名是否会下降。如果显著下降了,说明它是个有效的区块。
这仅是我的想法。而在实际实现上面,并没能实现有效的预测,我不确定是深度学习天生注定学习不到这样的因果关系,还是模型神经元过少等等其它的问题。毕竟我在机器学习方面的经验过于浅薄。
让文章继续回到探讨确定比较靠谱的那部分方面来。
往往越是朴素的方法,越是有效。因此,可以回过头看下溯因推理常见的基本流程。
通过归纳法观察到某一现象 ->
提出某个假说来解释这个现象 ->
通过这个假说提出某个推论 ->
通过归纳法来尝试证伪这个推论
突发性的降权分析是最为典型的溯因分析:
观察到一批网站的排名在同期下降这一现象;
发现它们共同具有某一特征,因此认为这一特征可能是降权原因;(穆勒五法里面的契合法)
(此例中一般没有进一步可衍生的推论,可以直接尝试证伪假说)
再找一批同期下降的网站,看是否每一个网站上都存在着这一特征。只要其中存在任何一个网站不存在这一特征,假说直接被完全证伪;反之,如果没有找到任何一例反例,那么假说靠谱的可能性随着被分析网站数量的增加而增加。
通过这样的方式,我曾经做过不少降权分析的事情。当然,其中还是涉及到不少SEO这个领域独特经验的,诸如不同的下降周期、不同词数分布区间的下降程度都说明不同的下降情况,有这些经验在,能帮助我更为快速精确的定位降权原因。但归根到底,这些SEO的经验,最初还是来自于过往大量基于溯因逻辑的分析,才被收集起来的。
基于溯因推理的基本流程,其中几个步骤都是有优化空间的。比如,是否可以自动的提出假说?是否能提出什么巧妙的推论,从而鉴别相关和因果关系之间的差别?
在这两个问题上,我这些天都有了根本的突破,颇有感触。因此想起来写下本文,以简述一些我之前在溯因推理这一方向上做过的研究探索。
当然读者极有可能有一个困惑是,把SEO这种东西研究到这种程度,有什么用?毕竟行业里面时常会看得到一些研究纯理论性东西的人,他们通常没什么流量成果。
理论脱离实践,在我刚做SEO的头两年是大量存在的。那时候,刚接触这行比较起劲,只要别人不研究的东西,我都想去研究,就是觉得那些东西有意思。但哪一行做个十多年没职业倦怠的,一个东西如果没有足够多的预期流量收益,现在我是压根懒得研究的。
我最近在做些很高竞争的行业,因此又再研究了不少。此前多年,我只能把大型网站的流量快速翻倍,但对于基础差的小网站很头疼。而现在,我已经做到了可以用小网站,在页面收录之时即超过高竞争行业的大部分头部巨型网站的排名。
题外话:
这些年百度收录门槛越来越高,大部分情况下我还是很能搞定收录的,毕竟多年经验在,但也有遇到些搞不定的问题。收录不像排名,不容易用溯因推理等分析方法来分析,现在对我反而是不小的阻碍。
最近有遇到一个问题是,收录进去的页面会被百度定期删除,手头有两个网站存在这样的状况。目前完全没有发现规律。甚至有本身内容质量过关,且每天几千几万流量的单个详情页面,仍突然被删除收录,鉴于此似乎应该认为是百度的bug,但无从排查。
如果有人有相关经验,希望能交流,我肯定能有其它方面的经验来互换。